WBZ
Check the article here: How to Build a Lossless Data Compression and Data Decompression Pipeline
A parallel implementation of the bzip2 data compressor in python, this data compression pipeline is using algorithms like Burrows–Wheeler transform (BWT) and Move to front (MTF) to improve the Huffman compression. For now, this tool only will be focused on compressing .csv files and other files on tabular format.
Data pipeline compression
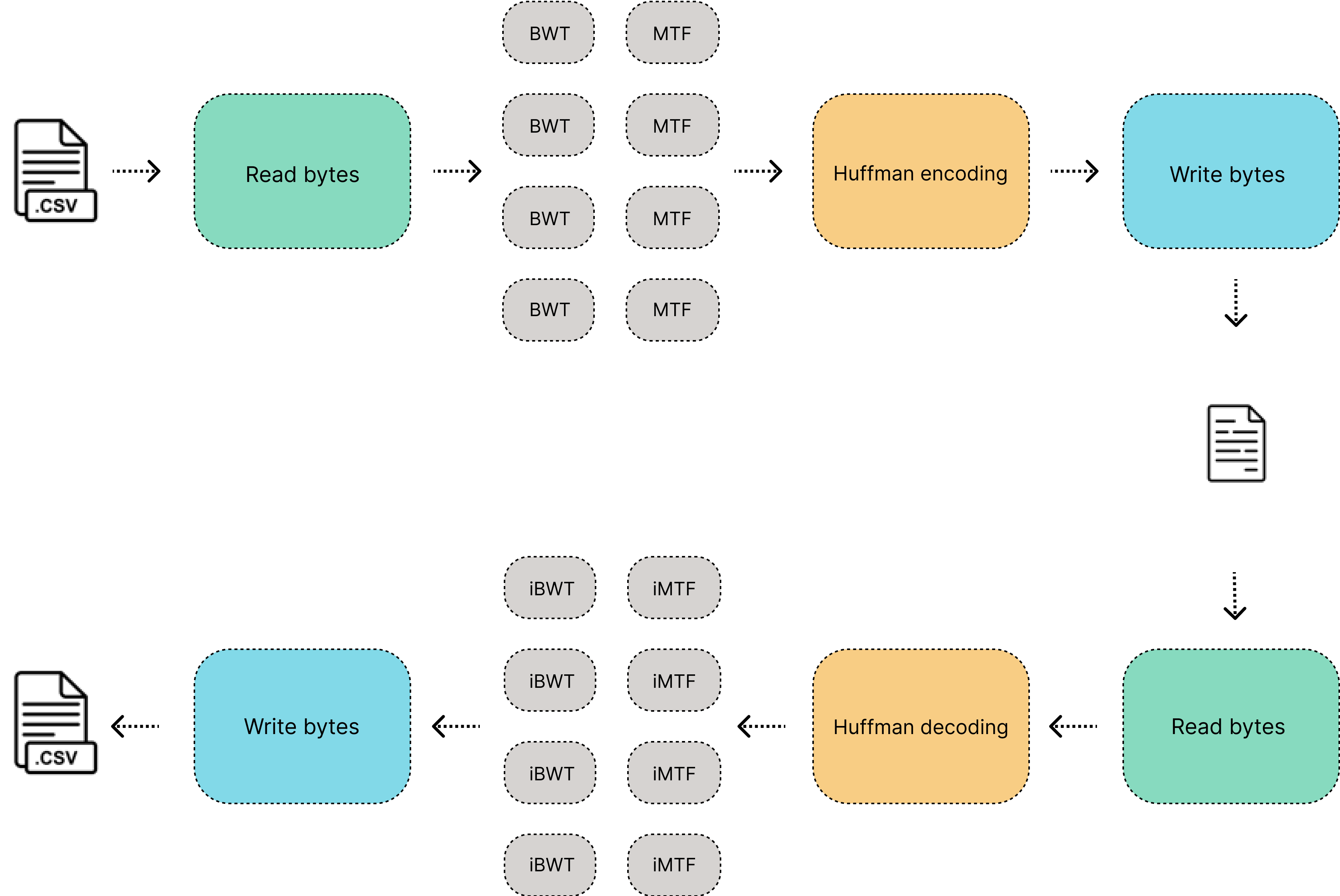
How to use the tool
The tool is called WBZ, the first version only will be focused in compressing .csv files and I will be adding more features coming soon, the parameters are described as follow:
python wbz.py -a encode -f 'C:\Users\...\data.csv' -cs 20000 -ch ';'
python wbz.py -a decode -f 'C:\Users\...\data.wbz' -cs 20000 -ch ';'
- -a is action , there is two actions: encode and decode
- -f is filepath, if your action is encode make sure that the filepath choosed is a .csv file, if your action is decode make sure that you choosed filepath is a file with extension .wbz
- -cs is chunk size, the algorithm Burrows–Wheeler transform (BWT) works with chunks sized in bytes, with this parameter you would specify the number of bytes to be processed by each CPU.
- -ch is special character, each chunk encoded by the algorithm Burrows–Wheeler transform (BWT) will contain an special character inside it, it will help to identify an index for decodeding purposes, The possible column separator characters in your .csv file could work as a special character, it is recommended to use a separator that is not used by your columns and that does not appear in the content of the columns, this feature will be removed in the next versions of this tool.
The same chunk size and special character used for encode the file must be used for decode the file, The idea of keep them as parameters is to be able to get a better trade-off of the speed in the encoding and decoding process and a better compression rate.
Performance
The tests were done with three .csv files of different sizes and varying the chunk size:
- data_1000000: One million records (61mb)
- data_500000: Half a million records (31 mb)
- data_250000: A quarter of a million records (16 mb)
There is an improvement in the rate compression for larger chunk sizes.

The compression times increase with a logarithmic behavior when the size of the chunk is increased as well.

Regardless of the size of the file, the decompression times have a constant behavior and tend to be reduced when the size of the chunk increases as well.

To-Do List:
- Improve the compression times of huffman and BWT encoding times.
- Improve the encode of the huffman table
- Compression based on columns
- Compress and decompress specific columns on the .csv file
- Generate compressed chunks automatically for large files
- Distributed compression and decompression
Contributing and Feedback
Any ideas or feedback about this repository?. Help me to improve it.
Authors
- Created by Ramses Alexander Coraspe Valdez
- Created on 2022
License
This project is licensed under the terms of the Apache License.