import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import math
A. Application of Improved Multiple Linear Regression Method in Oilfield Output Forecasting.¶
Liang Guo, Xianghui Deng. 2009 IEEE, DOI: 10.1109/ICIII.2009.39. pp 133-136. https://ieeexplore.ieee.org/document/5370533 This paper uses a multiple linear regression model to predict production of an oil field, the coefficients of the linear regression model are calculated using matrix operations which they call Model A, and some coefficients of the general model are discarded and now called Model B. The last model B has more predictive power because it has a lower average percentage of error.
B. When we want to implement an algorithm or methodology published in an article, the first thing to do is repeat the ideas proposed by the authors with the same data they used to ensure that we are understanding and implementing it correctly. In this exercise we will repeat what was done by the authors of this article in order to validate and better understand what they did. That is, using the data they indicate, you must obtain the same equation (10) of multiple linear regression that they indicate on page 135. As there are really few data, the authors obtain the coefficients of the regression model using the pseudoinverse matrix, as It is explained in the article. In the article, the authors say that this equation was obtained with data from the years from 1983 to 2001, when they actually used data from 1980 to 2001, and erroneously did not publish the missing years in the table on page 135. That is, you must apply the multiple linear regression method with the data from the years 1980 to 2001 and obtain the regression equation shown on page 135. Note that for this section you should only use the data from 1980 to 2001, because they are those they use as training data.¶
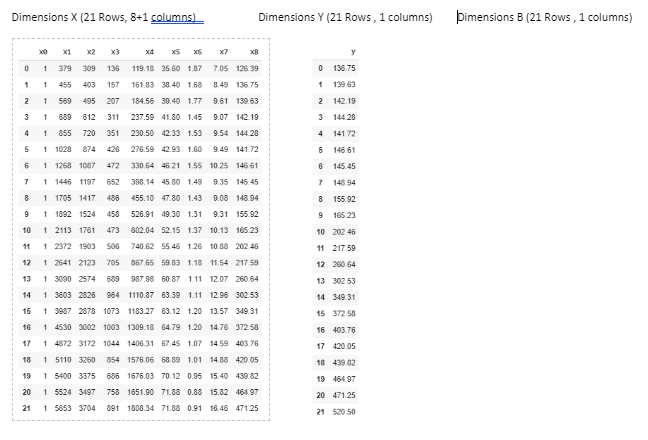
df1 = pd.read_csv('https://raw.githubusercontent.com/Wittline/Machine_Learning/master/Multiple%20linear%20regression/data.csv',
sep=',',
names=["year", "x1", "x2", "x3", 'x4', 'x5', 'x6', 'x7', 'x8', 'y']);
df1
x= df1[df1['year']<2002]
x= x.filter(['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8'])
x.insert(0, 'x0', 1)
y= df1[df1['year']<2002]
y= y.filter(["y"])
x
y
x_t = x.transpose()
x_t_x= x_t.dot(x)
x_t_y= x_t.dot(y)
x_t_x_inv = pd.DataFrame(np.linalg.pinv(x_t_x.values), x_t_x.columns, x_t_x.index)
x_t_x_inv_x_t = x_t_x_inv.dot(x_t)
betas= x_t_x_inv.dot(x_t_y)
betas
C. Indicate the dimensions of each of the following matrices, in the case of training data from 1980 to 2001:¶

D. Calculate the value of the matrix determinant 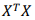 and the product
and the product 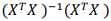 According to these two results, what can you say about the convenience of using the pseudo-inverse method to obtain the solution of this linear least squares regression problem? Do you consider it reliable? Explain your conclusions.
According to these two results, what can you say about the convenience of using the pseudo-inverse method to obtain the solution of this linear least squares regression problem? Do you consider it reliable? Explain your conclusions.
The determinant of matrix is different of null, For this reason using the pseudo-inverse is reliable, since there are no several solutions to the problem
det_x_t_x = np.linalg.det(x_t_x)
det_x_t_x
x_t_x_inv_x_t_x = x_t_x_inv.dot(x_t_x)
x_t_x_inv_x_t_x
E. Get the 8 Pearson correlation coefficients of the variable 𝑌 with respect to each of the 8 independent variables Xi. Use only training data, using only data from 1980 to 2001.¶
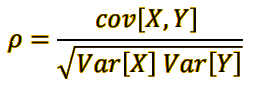
#Least square method
def Least_square(x,y):
mx = x.mean()
my = y.mean()
u=0
d=0
e=0
i=0;
while(i< len(x)):
u += ((x[i] - mx)*(y[i] - my))
d += ((x[i] - mx)**2)
e += ((y[i] - my)**2)
i +=1;
return (u/math.sqrt((d*e))), u, d, e
p1 = Least_square(x.x1, y.y)
p2 = Least_square(x.x2, y.y)
p3 = Least_square(x.x3, y.y)
p4 = Least_square(x.x4, y.y)
p5 = Least_square(x.x5, y.y)
p6 = Least_square(x.x6, y.y)
p7 = Least_square(x.x7, y.y)
p8 = Least_square(x.x8, y.y)
print("P1: ", p1[0], "P2: ", p2[0], "P3: ", p3[0], "P4: ", p4[0],"P5: ", p5[0],"P6: ", p6[0],"P7: ", p7[0], "P8: ", p8[0])
F. Get the 8 scatter plots of each of the independent variables 𝑋i, with respect to the variable 𝑌.¶
All the variables are highly correlated with the variable Y, The which one shows a negative correlation coincides with the negative slope that in this case is the variable X6 that also has a negative correlation coefficient, the variable that showed less correlation was the variable X3.
fig = plt.figure()
fig, axes = plt.subplots(nrows=2, ncols=4, figsize=(22, 12))
plt.subplots_adjust(wspace=0.2, hspace=0.2)
axes[0, 0].scatter(x.x1, y.y, color='C0')
axes[0, 0].set_xlabel("X1")
axes[0, 0].set_ylabel("Y")
axes[0, 1].scatter(x.x2, y.y, color='C0')
axes[0, 1].set_xlabel("X2")
axes[0, 1].set_ylabel("Y")
axes[0, 2].scatter(x.x3, y.y, color='C0')
axes[0, 2].set_xlabel("X3")
axes[0, 2].set_ylabel("Y")
axes[0, 3].scatter(x.x4, y.y, color='C0')
axes[0, 3].set_xlabel("X4")
axes[0, 3].set_ylabel("Y")
axes[1, 0].scatter(x.x5, y.y, color='C0')
axes[1, 0].set_xlabel("X5")
axes[1, 0].set_ylabel("Y")
axes[1, 1].scatter(x.x6, y.y, color='C0')
axes[1, 1].set_xlabel("X6")
axes[1, 1].set_ylabel("Y")
axes[1, 2].scatter(x.x7, y.y, color='C0')
axes[1, 2].set_xlabel("X7")
axes[1, 2].set_ylabel("Y")
axes[1, 3].scatter(x.x8, y.y, color='C0')
axes[1, 3].set_xlabel("X8")
axes[1, 3].set_ylabel("Y")
plt.show()

G. The authors explain on pages 135 and 136 of the article a method (screening process) to discard some variables that they do not consider relevant for the linear model found, where at the end of this process they remain only with the variables they consider more important, in This case were 𝑋1, 𝑋2, 𝑋4, 𝑋8. Assuming that as an alternative method you would have used the criterion of leaving only the variables 𝑋i that have a Pearson correlation coefficient with the variable 𝑌, greater than 0.96, what variables would have remained in your model?¶
X1, X4, X7, X8¶
H. Use the linear regression equation (10), called Model A in the article (the one that uses the 8 independent variables), to validate this model with the Test Data used by the authors, that is, using only the data of the years 2002 to 2006. Also calculate the relative percent errors of these results. Compare these results that you obtained with the results obtained by the authors and shown in Table III on page 136. Which year or years show a considerable discrepancy between your results and those of the article? NOTE: The percentage relative error is calculated by the authors using the following operation: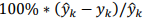
I. Repeat the previous experiment with the so-called Model B, that is, using equation 11 on page 136 of the article. Again compare your results with those shown by the authors.¶
In both cases Partially similar results are being obtained, the prediction for the year 2006 is different from the author, it is higher, therefore the percentage of error is higher.
def ModelA(x1,x2,x3,x4,x5,x6,x7,x8):
return (-63.325 - (0.0683*x1) + (0.0589*x2) + (0.0058*x3) + (0.2076*x4) - (1.0603*x5) + (58.2047*x6) + (0.5673*x7) + (0.8103*x8))
def ModelB(x1,x2,x3,x4,x5,x6,x7,x8):
return (-63.325 - (0.0683*x1) + (0.0589*x2) + (0.2076*x4) + (0.8103*x8))
def evaluate(d):
mA = [None] * len(d)
mB = [None] * len(d)
eA = [None] * len(d)
eB = [None] * len(d)
vy = [None] * len(d)
year = [None] * len(d)
for i in range(len(d)):
mA[i]= ModelA(d.iloc[i]['x1'], d.iloc[i]['x2'],d.iloc[i]['x3'],d.iloc[i]['x4'],d.iloc[i]['x5'],d.iloc[i]['x6'],d.iloc[i]['x7'],d.iloc[i]['x8']);
mB[i]= ModelB(d.iloc[i]['x1'], d.iloc[i]['x2'],d.iloc[i]['x3'],d.iloc[i]['x4'],d.iloc[i]['x5'],d.iloc[i]['x6'],d.iloc[i]['x7'],d.iloc[i]['x8']);
vy[i] = d.iloc[i]['y']
eA[i] = 100*((mA[i] - d.iloc[i]['y'])/mA[i])
eB[i] = 100*((mB[i] - d.iloc[i]['y'])/mB[i])
year[i] = d.iloc[i]['year']
return year, vy, mA, eA, mB, eB
data = df1[df1['year']>=2002]
year, vy, mA, eA, mB, eB = evaluate(data)
results = pd.DataFrame(list(zip(year, vy, mA, eA, mB, eB)),
columns =['Year', 'Output', 'Modelo A', 'Error', 'Modelo B', 'Error'])
results
J. What conclusions can you get from this Task and the process of repeating the tests of an article and trying to obtain the same results as the authors?¶
People trust the results of a scientific researching and almost never repeat the author's experiments, in this case I found discrepancies in the values that were predicted for the year 2006, which dramatically changed the expected error, and therefore also the error average, where both models have almost the same average percentage of error in their predictions.
K. What are your thoughts about this article published with missing data and results with clear discrepancies?¶
It is difficult to trust results where it is not clear how they used the dataset, sometimes the authors do not dedicate a paragraph to explain the origin and the real status of their dataset and that will always generate discrepancies in the experiments.