Installing libraries¶
In [233]:
# install.packages("tidyverse")
# install.packages("cluster")
# install.packages("factoextra")
# install.packages("corrplot")
# install.packages("party")
library(party)
library(tidyverse) # data manipulation
library(cluster) # clustering algorithms
library(factoextra) # clustering algorithms & visualization
library(corrplot)
In [234]:
normalize <- function(x) {
return ((x - min(x)) / (max(x) - min(x)))
}
Checking the data¶
In [235]:
countries.data <- read.csv("datasets_Country_data.csv", stringsAsFactors = F)
countries.dict <- read.csv("countries_dict.csv", stringsAsFactors = F)
countries.data <- transform(countries.data, income = as.numeric(income), gdpp = as.numeric(gdpp))
head(countries.data,10)
head(countries.dict,20)
In [236]:
countries <- countries.data$country
countries.data$country = NULL
countries.datan <- scale(countries.data)
row.names(countries.datan) <- countries
head(countries.datan,10)
Checking the correlations¶
In [237]:
source("http://www.sthda.com/upload/rquery_cormat.r")
col<- colorRampPalette(c("blue", "white", "red"))(20)
rquery.cormat(countries.datan, type="full", col=col)

Checking for multiple Clusters¶
In [238]:
set.seed(123)
k2 <- kmeans(countries.datan, centers = 2, iter.max = 25, nstart = 1)
k3 <- kmeans(countries.datan, centers = 3, iter.max = 25, nstart = 1)
k4 <- kmeans(countries.datan, centers = 4, iter.max = 25, nstart = 1)
k5 <- kmeans(countries.datan, centers = 5, iter.max = 25, nstart = 1)
k6 <- kmeans(countries.datan, centers = 6, iter.max = 25, nstart = 1)
# plots to compare
p1 <- fviz_cluster(k2, geom = "point", data = countries.datan) + ggtitle("k = 2")
p2 <- fviz_cluster(k3, geom = "point", data = countries.datan) + ggtitle("k = 3")
p3 <- fviz_cluster(k4, geom = "point", data = countries.datan) + ggtitle("k = 4")
p4 <- fviz_cluster(k5, geom = "point", data = countries.datan) + ggtitle("k = 5")
p5 <- fviz_cluster(k6, geom = "point", data = countries.datan) + ggtitle("k = 6")
library(gridExtra)
grid.arrange(p1, p2, p3, p4, p5, nrow = 3)

Checking for the appropiate number of clusters with the Elbow method¶
In [239]:
set.seed(123)
fviz_nbclust(countries.datan, kmeans, method = "wss")

Insights about the K choosed (K=3)¶
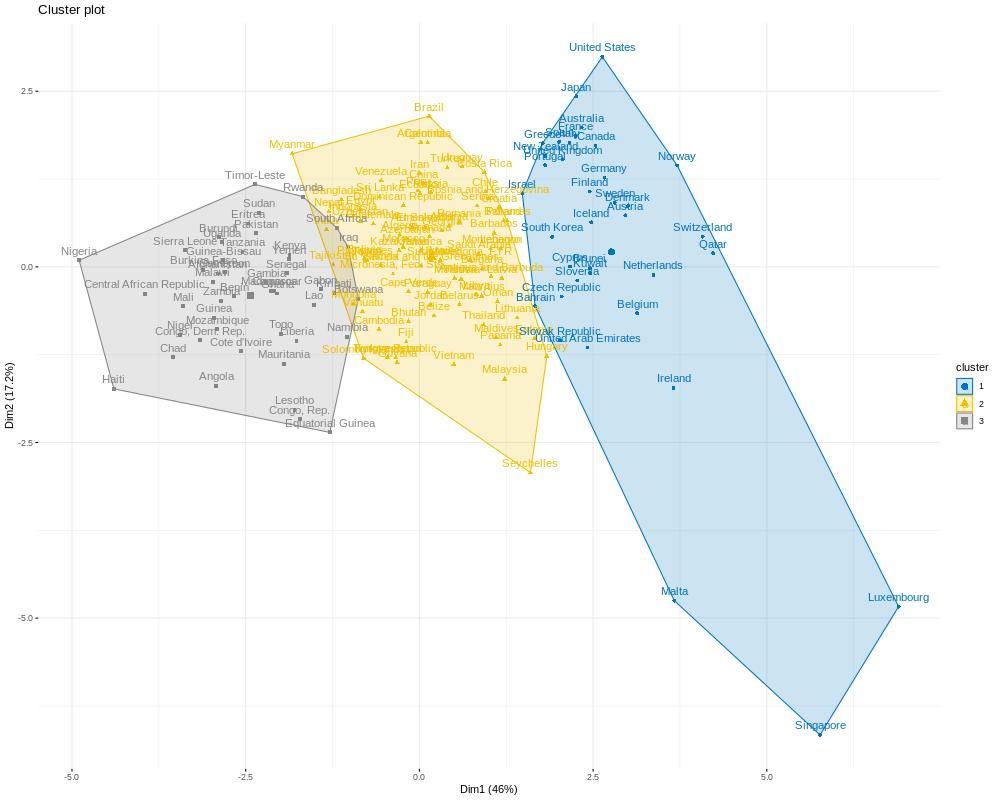
The countries will be separated in three groups:¶
Countries that do not need international HELP
Countries on the verge of needing international HELP
Countries that definitely need international HELP
Lets clarify some features of this analysis before choosing the groups:
- An higher inflation is bad
- An higher child mortality is bad
- An lower income is bad
In [240]:
set.seed(123)
k3 <- kmeans(countries.datan, centers = 3, iter.max = 25, nstart = 1)
attributes(k3)
k3$size
k3$centers
p2 <- fviz_cluster(k3, data = countries.datan,
ellipse.type = "convex",
palette = "jco",
ggtheme = theme_minimal())
p2

In [241]:
countries.datan <- cbind(countries.datan, cluster = k3$cluster)
countries.datan <- cbind(countries.datan, label = k3$cluster)
countries.datan <- as.data.frame(countries.datan)
countries.datan[countries.datan$cluster==1,]$label <- "non"
countries.datan[countries.datan$cluster==2,]$label <- "verge"
countries.datan[countries.datan$cluster==3,]$label <- "need"
countries.datan$label <- factor(countries.datan$label)
countries.datan <- cbind(countries.datan, country = countries)
The countries that urgently need international aid are those highlighted in the gray area, cluster number 3.¶
In [242]:
countries <- countries.datan[countries.datan$cluster==3,]$country
countries
Implementing CART¶
In [243]:
countries.datan$country <- NULL
In [244]:
set.seed(1234)
ind <- sample(x=c(1,2), size=nrow(countries.datan), replace=TRUE, prob=c(0.7, 0.3))
training.set <- countries.datan[ind==1,]
test.set <- countries.datan[ind==2,]
In [245]:
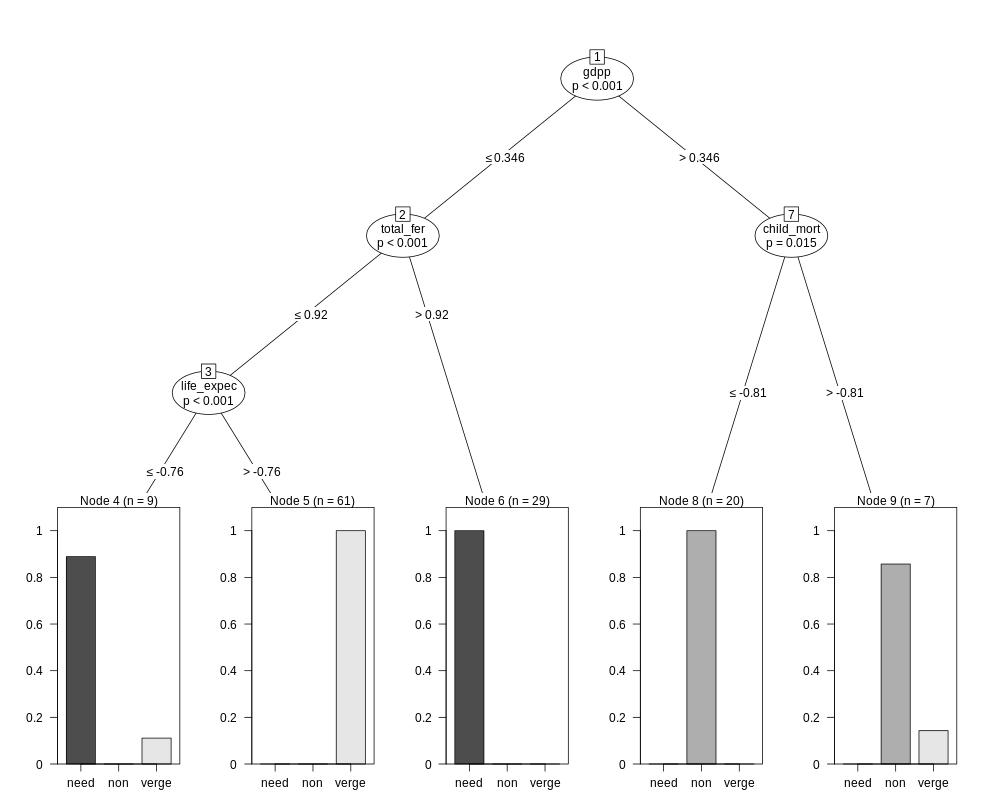
formula.1 <- label ~ child_mort + exports + health + imports + income + inflation + life_expec + total_fer + gdpp
countries_help.ctree <- ctree(formula = formula.1, data = training.set)
plot(countries_help.ctree)

In [246]:
train_predict <- predict(countries_help.ctree,training.set,type="response")
table(train_predict,training.set$label)
In [247]:
error_rate <- mean(train_predict != training.set$label) * 100
accuracy <- (100 - error_rate)
accuracy
In [248]:
test_predict <- predict(countries_help.ctree, newdata= test.set,type="response")
table(test_predict, test.set$label)
error_rate <- mean(test_predict != test.set$label) * 100
accuracy <- (100 - error_rate)
accuracy